Symbol search is too slow to provide jump-to-definition on torvalds/linux
Created by: chrismwendt
Problem
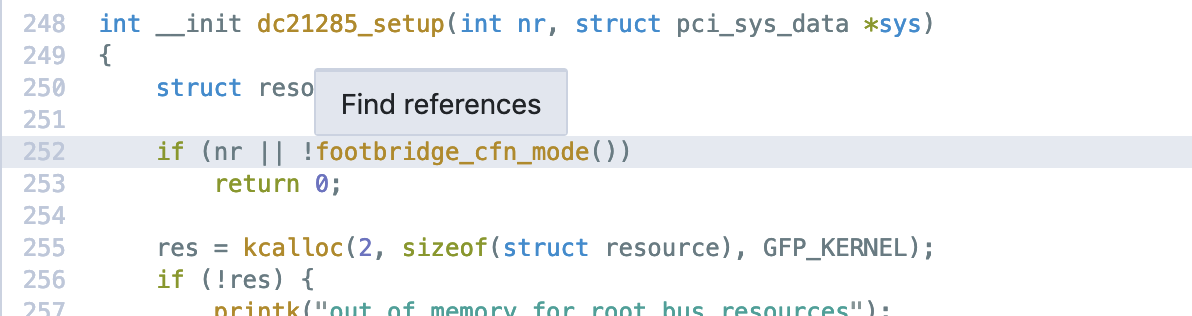
Jump-to-definition doesn't work on torvalds/linux (e.g. dc21285.c#L252:13). This was reported by a user in https://github.com/sourcegraph/sourcegraph/issues/1625 and will likely be a showstopper for companies with monorepos. I expect a "Go to definition" button next to "Find references", but it actually isn't there:
Finding the bottlenecks
From the browser's perspective, the request took 10.15s:
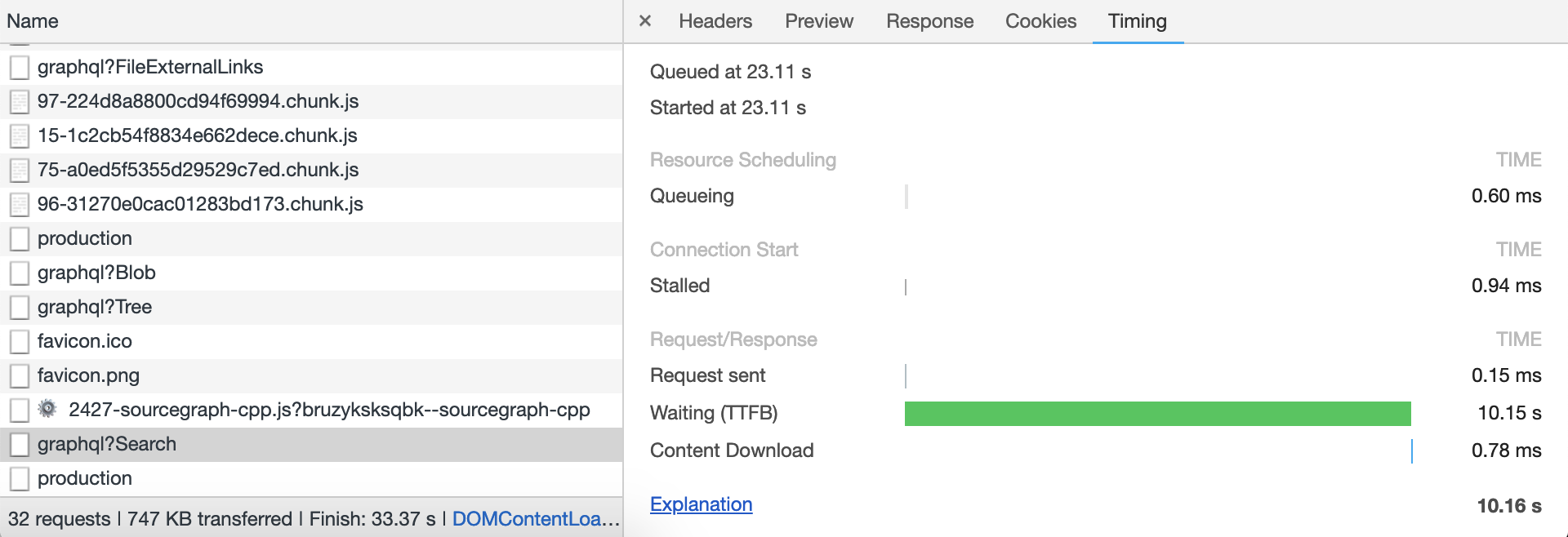
The query was: \bfootbridge_cfn_mode\b case:yes file:.(c|cc|cpp|hh|h)$ type:symbol repo:^github.com/torvalds/linux$@aa0c38cf39de73bf7360a3da8f1707601261e518
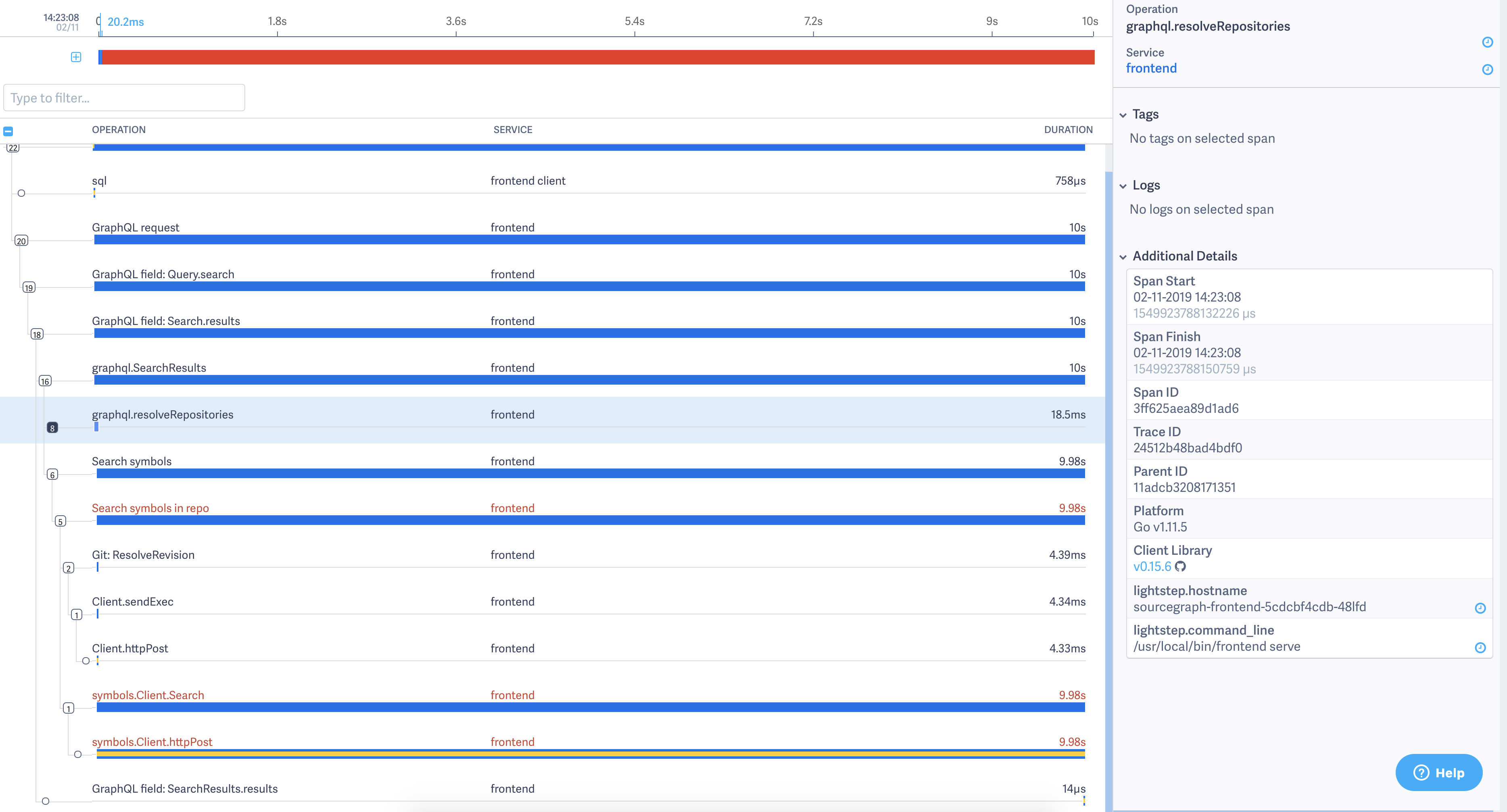
The LightStep trace from the x-trace header in the HTTP response shows that 99% of the time was spent blocked on a symbols.Client.httpPost:
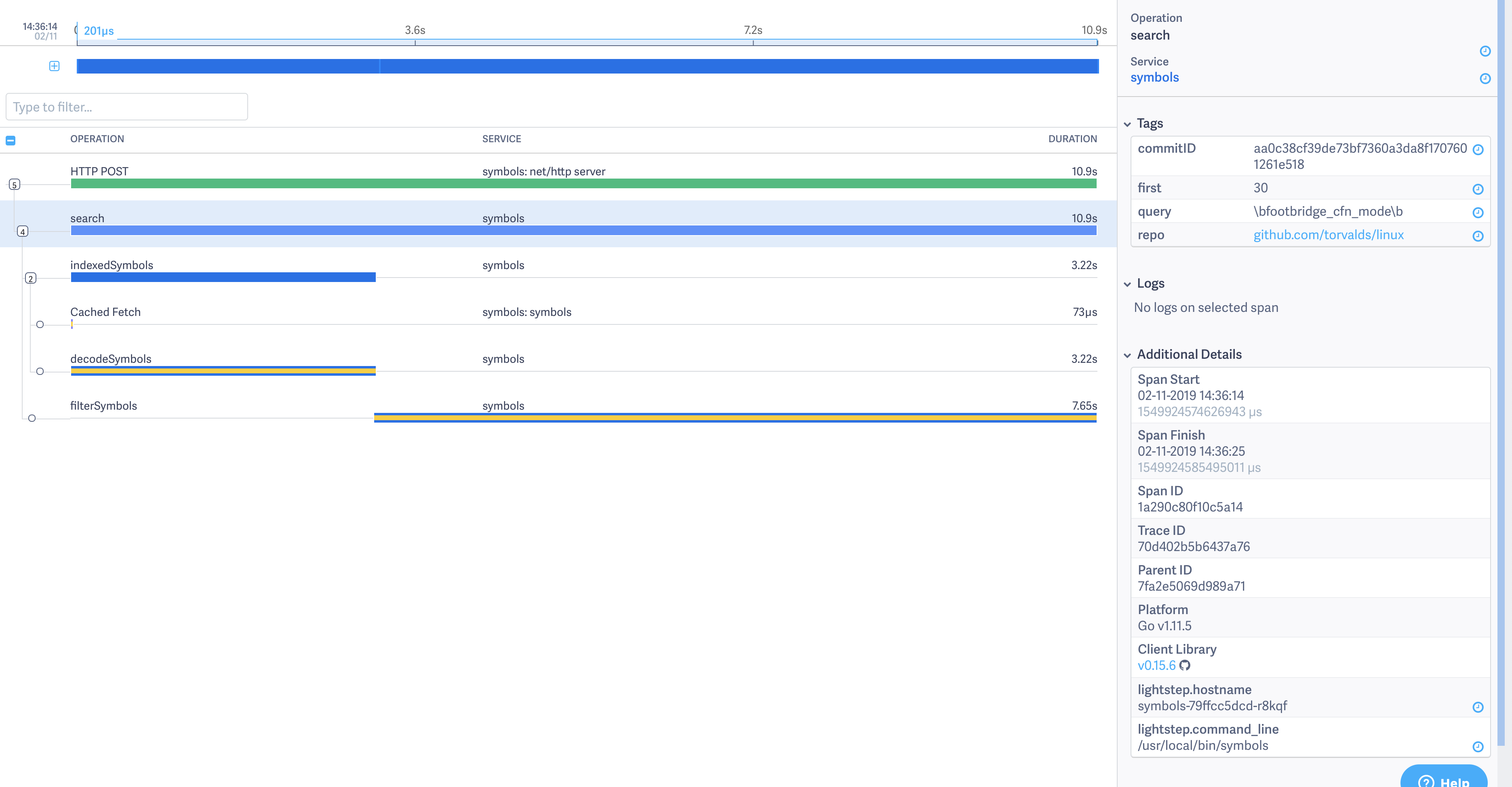
I later found the rest of the trace through LightStep's UI (and filed https://github.com/sourcegraph/sourcegraph/issues/2248), and this trace shows 30% of time spent in decodeSymbols and 70% of time spent in filterSymbols:
Understanding how the symbols service works
Parsing tags out of files
Parsing is triggered by a HTTP /search request.
The symbols service main process fetches a tar from gitserver and passes file contents over stdio to N child ctags processes running in interactive mode in parallel.
The ctags processes pass tags back to the main process over stdout, and the main process collects all the tags in a giant slice of symbols in Go then gzips it and writes it to the disk cache at /mnt/cache/symbols-$POD/$REPO_HASH.zip.
Querying tags
Queries are served on the HTTP /search endpoint.
The main process reads and decodes (decodeSymbols) the giant slice of symbols from the disk cache then filters (filterSymbols) them by looping over each symbol and matching against the given regexes. The main problem is that to find even a single symbol, it has to load the entire cache archive into memory at once and loop over each symbol. The symbols are neither sharded nor indexed.
Ideas for improvements
There 2 primary use cases to support:
- Find an exact symbol (needed by basic code intel)
- List all the symbols in a file (needed by the symbols view in the future, once it's scoped to the current file)
Sharding by symbol name and/or file path
The symbols service could hash symbol names into N buckets and write N tars to disk (with the same slice-of-symbols format). It could also do the same for file paths (using 2x disk space). That way, the symbols service would only need to read 1 of those N tars to find an exact symbol or for symbols in an exact file.
Indexing by symbol name and/or file path
Instead of only a slice-of-symbols format, the symbols service could also write an index into the file:
type NewFormat struct {
Symbols []protocol.Symbol // same as current format
SymbolNameIndex map[string][]int // symbol name to list of indexes into .Symbols of symbols that have that name
FilePathIndex map[string][]int // file path to list of indexes into .Symbols
}That would slow down decodeSymbols a little bit (have to also decode the 2 indexes), but would make filterSymbols nearly constant-time.
Separate index files
The same as the previous section, but put each map[string][]int in a separate file and make the int refer to a byte offset in the slice-of-symbols file (rather than an index) so that the symbols service can seek + read a tiny part of the file.
Micro-optimizations
From @slimsag:
I think just from implementing exact string matching, or even substring matching, you would skip the cost of regex matching 200k+ symbol paths/names and would see gains of 50-65% in terms of time to result
also note
symbols []protocol.Symbolis used everywhere, which means e.g. looping oversymbolswith a for loop causes everyprotocol.Symbolto be copied, and each one contains several fields, so 8+8+8+8+8+8+8+8+8+1 bytes being copied around for every one. It may be worth testing perf if you change those to pointers
Other nasty stuff here includes every symbol having its own
LanguageandPathstrings, despite the high odds they will all have close to the same ones, etc
From @keegancsmith
Yeah this line in particular is bad https://sourcegraph.com/github.com/sourcegraph/sourcegraph/-/blob/cmd/symbols/internal/symbols/search.go#L134 Stop starting a regex engine is slow, and we do it for lots of small strings (symbol name). I would suspect if we were to adjust the symbols search to just re-use searcher it would be much faster.
Zoekt supports ctags
From @keegancsmith:
zoekt already has support to take the output of ctags
Postgres
TODO @slimsag to fill in
Refs
- https://github.com/sourcegraph/sourcegraph/issues/1625
- https://github.com/sourcegraph/sourcegraph/issues/1738
- https://github.com/sourcegraph/sourcegraph/issues/1964
- https://sourcegraph.slack.com/archives/C07KZF47K/p1549409281707800 (research by @slimsag)
- https://sourcegraph.slack.com/archives/C0C324C91/p1549917863003300 (lots of ideas for improving symbol search)