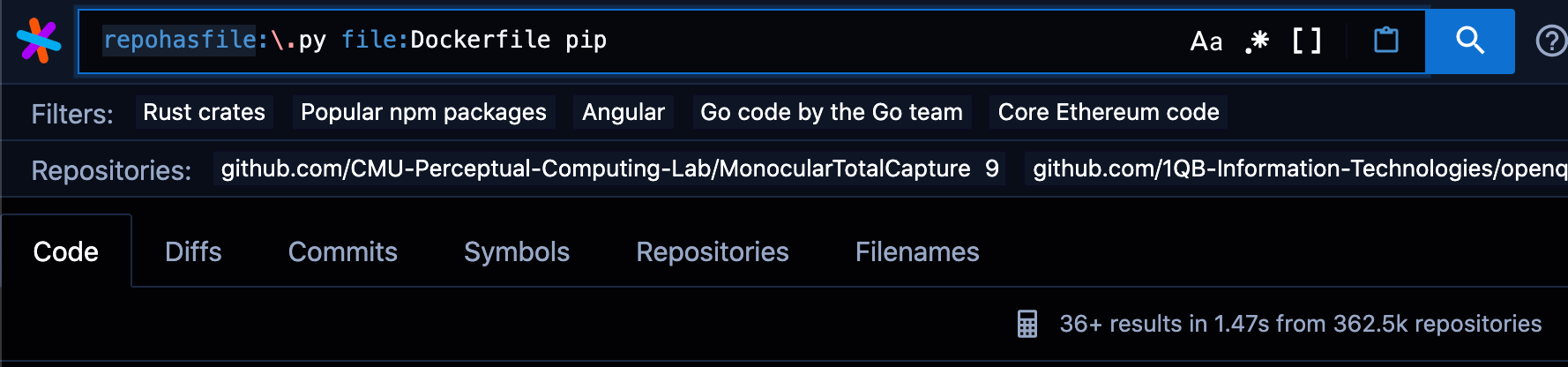
Perf/UX concerns for `contains` predicate
Created by: rvantonder
I think we didn't investigate the perf difference sufficiently for the contains implementation. I want to deprecate our repoHasFile parameter but I'm running into behavior that isn't great in the new implementation. Either we need to improve these, or replace our implementation by substituting the existing repoHasFile to get the backend logic to perform at the same level, and then remove the query processing and definitions for repoHasFile, etc. Issues:
(1) New implementation only reports 30 repositories--this is probably because of the substitution operation not merging or propagating the repos being searched. When modified to count:100, it reports 100 repositories. This is primarily a UX issue. The previous alternative reports the 300K+ repositories we search against.
(2) Then there is a perf difference--generally the older implementation is faster. I mentioned in https://github.com/sourcegraph/sourcegraph/issues/18584:
Extra notes: it'd be worthwhile to look at how repoHasFile is currently implemented. I don't think we can reuse much of this code, but it would be interesting if we can learn anything about how it optimizes this use case, and maybe we can borrow parts of the approach.
I'm wondering if we can borrow anything here to run similar faster code for contains.content, so that we can call out to that instead.
new

old